기본 기능 구현 완료
단계 별 계획
그냥 단순히 계획한대로 처음부터 큰 규모를 만들려고 하지 않을 것이다. 이유는 성능 개선에 있어서 어떤 문제가 있었고 어떻게 개선했고 왜 이런 방법을 사용했는지에 대한 물음에 대답을 할 수 있기 위함도 있고, 단계별로 어떤식으로 개선했는지를 보여주면 너무 좋은 프로젝트가 될 것 같다는 생각 때문이다.
1단계 : 기본 구현 및 초기 성능 테스트
설명
- 이 단계는 우리가 흔히 볼 수 있는 java + spring 조합으로 기본적으로 구현한 코드를 구현한 상태에서 테스트를 진행하는 단계이다.
- 아직은 redis 사용하지 않은 상태이다.
- 단순히 자바 또는 스프링 프레임워크 단계에서 처리할 수 있는 애플리케이션 레벨의 동시성 제어와 DB 수준의 락을 사용한 동시성 제어
코드
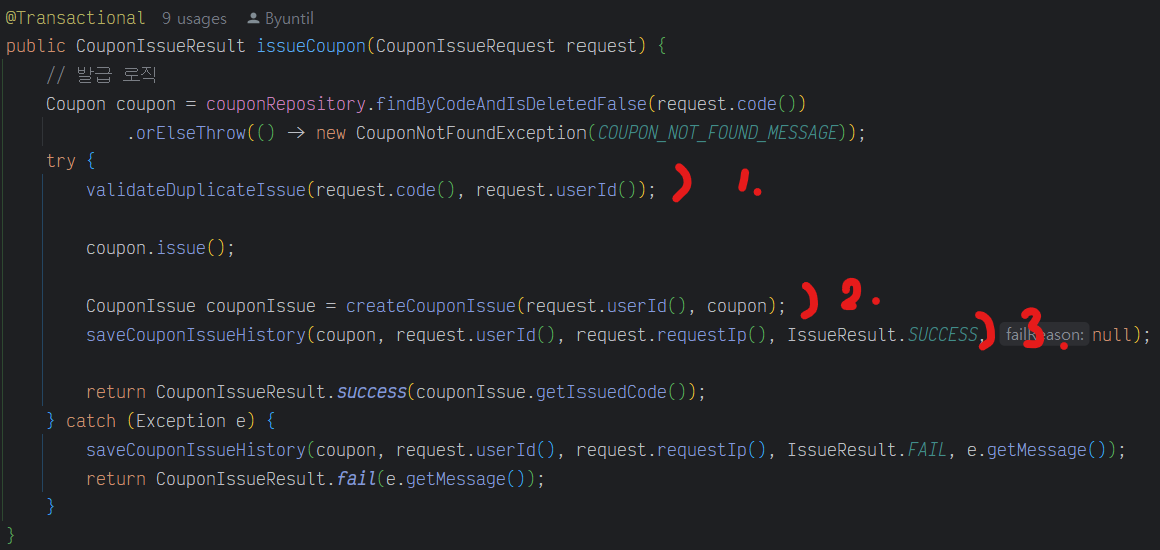
CouponService.java1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// 쿠폰 발급 @Transactional public CouponIssueResult issueCoupon(CouponIssueRequest request) { // 발급 로직 Coupon coupon = couponRepository.findByCodeAndIsDeletedFalse(request.code()) .orElseThrow(() -> new CouponNotFoundException(COUPON_NOT_FOUND_MESSAGE)); try { validateDuplicateIssue(request.code(), request.userId()); coupon.issue(); CouponIssue couponIssue = createCouponIssue(request.userId(), coupon); saveCouponIssueHistory(coupon, request.userId(), request.requestIp(), IssueResult.SUCCESS, null); return CouponIssueResult.success(couponIssue.getIssuedCode()); } catch (Exception e) { saveCouponIssueHistory(coupon, request.userId(), request.requestIp(), IssueResult.FAIL, e.getMessage()); return CouponIssueResult.fail(e.getMessage()); } }CouponRepository.java1
2
3
4
5@Repository public interface CouponRepository extends JpaRepository<Coupon, Long> { @Query("SELECT c FROM Coupon c WHERE c.code = :code AND c.isDeleted = false") Optional<Coupon> findByCodeAndIsDeletedFalse(String code); }테스트 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24@Test @DisplayName("쿠폰 발급 성공") void issueCoupon_success() { // when CouponIssueResult result = couponService.issueCoupon(new CouponIssueRequest(code, userId, requestIp)); // then assertThat(result.isSuccess()).isTrue(); // DB 확인 CouponIssue savedCouponIssue = couponIssueRepository.findByIssuedCodeAndUserId(result.getCouponCode(), userId) .orElseThrow(); assertThat(savedCouponIssue.getUserId()).isEqualTo(userId); Coupon updatedCoupon = couponRepository.findByCodeAndIsDeletedFalse(code) .orElseThrow(); assertThat(updatedCoupon.getRemainStock()).isEqualTo(9); // 히스토리 확인 CouponIssueHistory history = couponIssueHistoryRepository .findByCouponCodeAndUserId(code, userId) .orElseThrow(); assertThat(history.getResult()).isEqualTo(IssueResult.SUCCESS); }- 쿠폰 하나를 발급 하는데는 테스트 성공을 한다.
문제 상황
1 | |
- 멀티 스레드 사용해서 2개를 동시에 발급을 하면
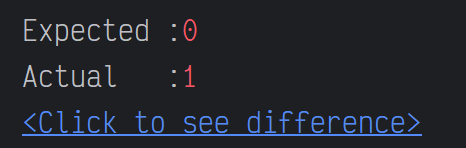 -> 테스트를 실패한다. 분명 동시에 2개의 요청이 들어오면 남는 재고는 0개가 되어야 하는데 실제로는 1개만 처리 되었다.
왜 이런 문제가 발생했고 어떻게 해결할 수 있을까?
-> 테스트를 실패한다. 분명 동시에 2개의 요청이 들어오면 남는 재고는 0개가 되어야 하는데 실제로는 1개만 처리 되었다.
왜 이런 문제가 발생했고 어떻게 해결할 수 있을까?

왜 실패?
당연하게도 couponService의 쿠폰 발행하는 부분에서 race condition이 발생하기 때문이다. 여기서 왜 race condition이 발생할까? 그 이유는 같은 자원을 여러 스레드가 동시에 접근하려는 상황이 생기기 때문이다. 이런 경우 동기화 문제가 생길 수 있는데 이 동기화 문제는 재현이 되지 않아서 해결이 어렵다. 그래서 공유자원을 파악하고 이 자원에 접근할 때 race condition이 발생하지 않게 구현하는게 중요하다.
지금의 경우는 크게 두 부분에서 문제가 생길 수 있다
1. 쿠폰 발급 과정
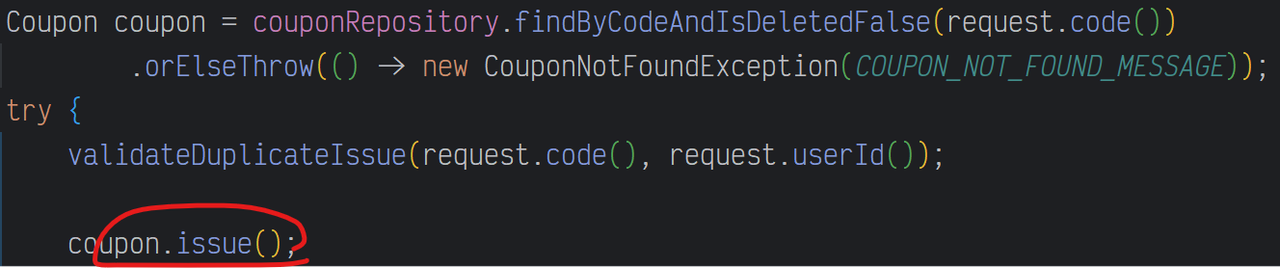
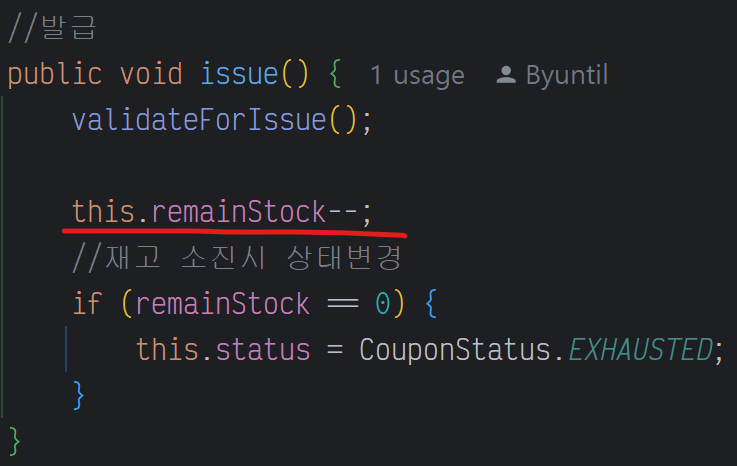
this.remainStock-- : 이 부분이 원자적(Atomic)이지 않다.
원자성(Atomic) : 이 연산을 수행을 할 때는 부분적으로 실행되다가 중단 되지 않는 것을 보장
예를 들어
- 스레드 A가 remainStock이 5일 때 읽고
- 스레드 B도 동시에 remainStock이 5인 것을 읽었다
- 스레드 A는 remainStock– 수행하여 4로 업데이트 한다
- 스레드 B도 remainStock– 수행하여 4로 업데이트 한다
- 결과적으로 두 번의 발급이 이루어졌지만 재고는 1만 감소한다.
2. Coupon 찾기 로직과 쿠폰 발행 사이의 시간 간격
예를들어
- 스레드 A가 쿠폰을 조회함 => 현재 Coupon 남는 재고 : 1개
- 그 때 스레드 B가 쿠폰을 조회함 => 현재 Coupon 남는 재고 : 1개
- 스레드 A가 중복 검증 수행
- 스레드 B가 중복 검증을 수행
- 스레드 A가 issue() 메서드 실행(remainStock = 0)
- 스레드 B가 issue() 메서드 실행(remainStock = -1) => 데이터 정합성을 해침, 재고 범위 내에서 발급해야하는데 그 이상을 발급함, 검증을 이미 통과를 했는데도 발행 시점에서는 이미 남는 재고가 0임
그렇다면 어떻게 해결해야 할까??

동시성 문제 해결 방법 Lock
데이터 베이스같은 자원에 대한 동시성 문제를 해결하기 위해 사용하는 개념인 lock은 크게 Optimistic Lock과 Pessimistic Lock이 있다.
낙관적 락은 자원에 대한 충돌이 거의 발생하지 않을 것이라고 가정하고, 충돌이 발생할 때만 처리하는 방식 비관적 락은 자원에 대한 충돌이 자주 발생할 것을 가정하고, 자원에 접근할 때마다 락을 거는 방식
낙관적 락(Optimistic Lock)
- 주로 자원에 대한 접근이 빈번하지 않을 경우에 사용됨 자원에 대한 접근이 빈번하지 않는다는 의미는 그만큼 충돌이 생길 가능성이 적다는 의미
비관적 락(Pessimistic Lock)
- 주로 자원에 대한 접근이 빈번한 상황에 사용됨 자원에 대한 접근 빈번하다는 의미는 그만큼 충돌이 생길 가능성이 높다는 의미
그렇다면 다시 돌아와서 쿠폰 발행하는 경우는 어떤 락을 적용해야 할 까? 당연히 비관적 락이다. 왜냐하면 한정판 쿠폰의 경우 한 순간에 엄청난 트래픽이 몰릴 수 있기 때문에 비관적 락을 사용해야한다.
비관적 락 적용
 데이터베이스에서 쿠폰을 조회를 하는 부분에 jpa에서 제공하는
데이터베이스에서 쿠폰을 조회를 하는 부분에 jpa에서 제공하는 @Lock(LockModeType.PESSIMISTIC_WRITE) 로 적으면 비관적 락이 적용이 된다.
jpa는 select 쿼리 실행시 SELECT FOR UPDATE 구문을 사용한다.
SELECT FOR UPDATE 는 데이터베이스 수준에서 해당 row에 대한 배타적 락을 거는 것이다. 이것은 트랙션이 완료될 때까지 다른 트랜잭션이 해당 row를 수정하지 못하도록 하는 것이다
배타적 락 : lock을 가지고 있다면 다른 트랜잭션은 해당 자원을 점유 할 수 없다.
따라서 remainStock-- 연산을 진행하고 최종적으로 트랜잭션이 커밋이 될때 한번에 데이터베이스에 update 쿼리를 날린다.
실제 쿼리를 확인 해보자
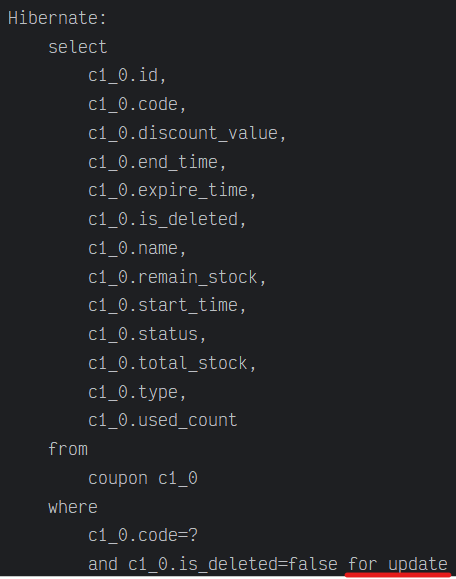 쿠폰을 조회할때 for update 구문을 확인 할 수 있다.
쿠폰을 조회할때 for update 구문을 확인 할 수 있다.
바로 이어서 각각의 쿼리는
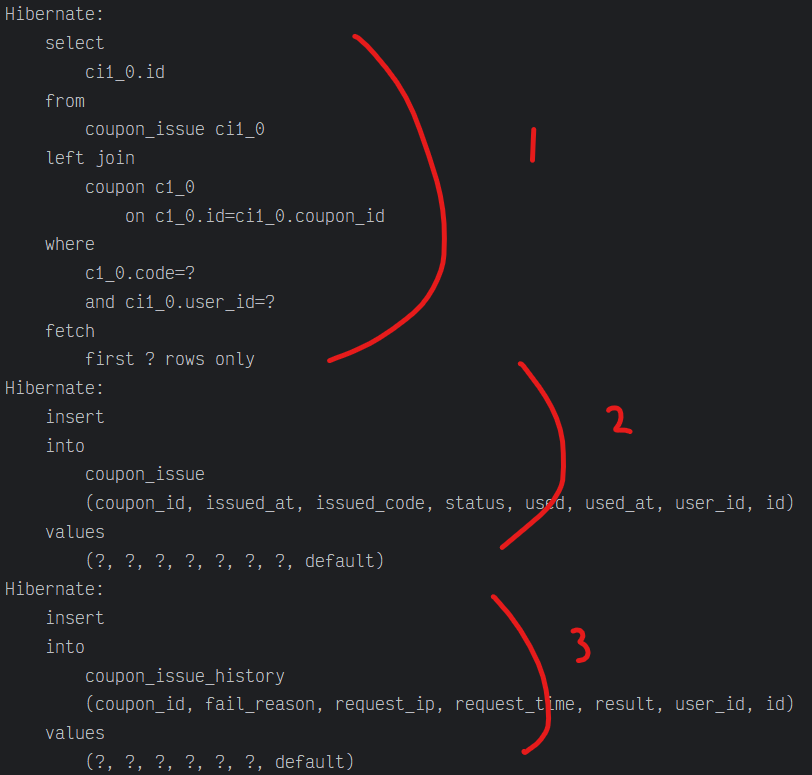
 바로 이어서
바로 이어서
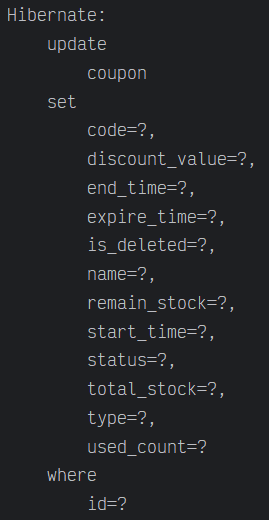 이렇게 한번에 update 쿼리가 나간다. 이 이후 다음 트랜잭션을 처리하게 된다.
이렇게 한번에 update 쿼리가 나간다. 이 이후 다음 트랜잭션을 처리하게 된다.
 정리하면 쿠폰을 조회하는 시점부터 update 쿼리가 나갈 때까지 해당 row는 lock을 가지고 있어 다른 트랜잭션은 자원을 점유하고 있지 못한다.
정리하면 쿠폰을 조회하는 시점부터 update 쿼리가 나갈 때까지 해당 row는 lock을 가지고 있어 다른 트랜잭션은 자원을 점유하고 있지 못한다.
만약 락을 사용하지 않는다면?
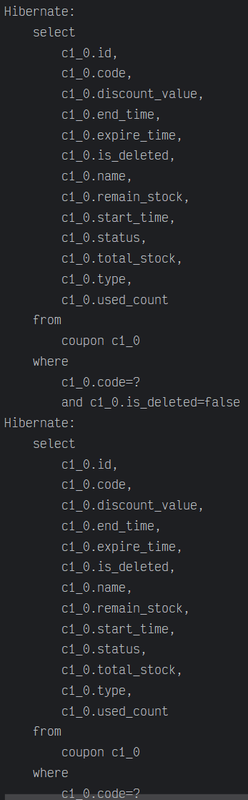 조회를 했는데 또 조회를 하는 모습을 볼 수 있다. 당연히 우리가 원하는 결과를 얻을 수 없다.
조회를 했는데 또 조회를 하는 모습을 볼 수 있다. 당연히 우리가 원하는 결과를 얻을 수 없다.
한계
1단계 단순히 DB 수준의 배타적 락을 건다면 어떤 한계가 있을까?
예측할 수 있듯이 만약
락을 얻고 1번 과정이 오래 걸린다거나 아니면 다른 이유로 많은 시간이 소요된다면 다른 트랙재션은 그동안 락을 계속 기다려야 하는 상황이 생긴다. 따라서 많은 요청이 동시에 들어올 때 시스템 성능이 크게 저하될 수 있다.
1 | |
- 데드락 발생 가능성
- lock이 걸려서 더이상 진행이 안되는 상황….
- 데드락으로 인하여 자연스럽게 타임아웃 문제 발생
- lock을 계속 잡고 있기 때문에 데이터베이스 커넥션을 유지하고 있기 때문에 전체적인 시스템 리소스 활용이 비효율적임
등의 문제가 있을 수 있겠다..

해결방법
그렇다면 어떤 방법이 좋을까? 낙관적 락?? 충돌이 적게 일어날 것을 가정해서 충돌이 감지되면 처리하도록!! 하지만 이 방법은 위에서도 설명했지만 적절하지 않다 이유는 쿠폰 발급과 같이 동시 요청이 많은 경우 충돌이 빈번하게 발새하기 때문에 낙관적 락을 적용한다면 오히려 오버헤드가 커질 수 있다.
이에 대한 해결책은 다음편에서 계속…